One of the early design decisions made in OVN was to only support tunnel encapsulation protocols that provided the ability to include additional metadata beyond what fits in the VNI field of a VXLAN header. OVN mostly uses the Geneve protocol and only uses VXLAN for integration with TOR switches that support the hardware_vtep OVSDB schema to use as L2 gateways between logical and physical networks.
Many people wonder when they first learn of this design decision, “why not VXLAN?” In particular, what about performance? Some hardware has VXLAN offload capabilities. Are we going to suffer a performance hit when using Geneve?
These are very good questions, so I set off to come up with a good answer.
Why Geneve?
One of the key implementation details of OVN is Logical Flows. Instead of programming new features using OpenFlow, we primarily use Logical Flows. This makes feature development easier because we don’t have to worry about the physical location of resources on the network when writing flows. We are able to write flows as if the entire deployment was one giant switch instead of 10s, 100s, or 1000s of switches.
Part of the implementation of this is that in addition to passing a network ID over a tunnel, we also pass IDs for the logical source and destination ports. With Geneve, OVN will identify the network using the VNI field and will use an additional 32-bit TLV to specify both the source and destination logical ports.
Of course, by using an extensible protocol, we also have the capability to add more metadata for advanced features in the future.
More detail about OVN’s use of Geneve TLVs can be found in the “Tunnel Encapsulations” sub-section of “Design Decisions” in the OVN Architecture document.
Hardware Offload
Imagine a single UDP packet being sent between two VMs. The headers might look something like:
- Ethernet header
- IP header
- UDP header
- Application payload
When we encapsulate this packet in a tunnel, what gets sent over the physical network ends up looking like this:
- Outer Ethernet header
- Outer IP header
- Outer UDP header
- Geneve or VXLAN Header
- Application payload: (Inner packet from VM 1 to VM 2)
- Inner Ethernet header
- Inner IP header
- Inner UDP header
- Application payload
There are many more NIC capabilities than what’s discussed here, but I’ll focus on some key features related to tunnel performance.
Some offload capabilities are not actually VXLAN specific. For example, the commonly referred to “tx-udp_tnl-segmentation” offload applies to both VXLAN and Geneve. This is where the kernel is able to send a large amount of data to the NIC at once and the NIC breaks it up into TCP segments and then adds both the inner and outer headers. The performance boost comes from not having to do the same thing in software. This offload helps significantly with TCP throughput over a tunnel.
You can check to see if a NIC has support for “tx-udp_tnl-segmentation” with ethtool. For example, on a host that doesn’t support it:
$ ethtool -k eth0 | grep tnl-segmentation tx-udp_tnl-segmentation: off [fixed]
or on a host that does support it and has it enabled:
$ ethtool -k eth0 | grep tnl-segmentation tx-udp_tnl-segmentation: on
There is a type of offload that is VXLAN specific, and that is RSS (Receive Side Scaling). This is when the NIC is able to look inside a tunnel to identify the inner flows and efficiently distribute them among multiple receive queues (to be processed across multiple CPUs). Without this capability, a VXLAN tunnel looks like a single stream and will go into a single receive queue.
You may wonder, “does my NIC support VXLAN or Geneve RSS?” Unfortunately, there does not appear to be an easy way to check this with a command. The best method I’ve seen is to read the driver source code or dig through vendor documentation.
Since the VXLAN specific offload capability is on the receive side, it’s important to look at what other techniques can be used to improve receive side performance. One such option is RPS (Receive Packet Steering). RPS is the same concept as RSS, but done in software. Packets are distributed among CPUs in software before fully processing them.
Another optimization is that OVN enables UDP checksums on Geneve tunnels by default. Adding this checksum actually improves performance on the receive side. This is because of some more recent optimizations implemented in the kernel. When a Geneve packet is received, this outer UDP checksum will be verified by the NIC. This checksum verification will be reported to the kernel. Since the outer UDP checksum has been verified, the kernel uses this fact to skip having to calculate and verify any checksums of the inner packet. Without enabling the outer UDP checksum and letting the NIC verify it, the kernel is doing more checksum calculation in software. It’s expected that this regains significant performance on the receive side.
Performance Testing
In the last section, we identified that there is an offload capability (RSS) that is VXLAN specific. Some NICs support RSS for VXLAN and Geneve, some for VXLAN only, and others don’t support it at all.
This raises an important question: On systems with NICs that do RSS for VXLAN only, can we match performance with Geneve?
On the surface, we expect Geneve performance to be worse. However, because of other optimizations, we really need to check to see how much RSS helps.
After some investigation of driver source code (Thanks, Lance Richardson!), we found that the following drivers had RSS support for VXLAN, but not Geneve.
- mlx4_en (Mellanox)
- mlx5_core (Mellanox)
- qlcnic (QLogic)
- be2net (HPE Emulex)
To help answer our question above, we did some testing on machines with one of these NICs.
Hardware
The testing was done between two servers. Both had a Mellanox NIC using the mlx4_en driver. The NICs were connected back-to-back.
The servers had the following specs:
- HP Z220
- Intel(R) Core(TM) i5-3470 CPU @ 3.20GHz (1 socket, 4 cores)
- Memory: 4096 MB
Software
- Operating System: RHEL 7.3
- Kernel: 4.10.2-1.el7.elrepo.x86_64
- Used a newer kernel to ensure we had the latest optimizations available.
- Installed via a package from http://elrepo.org/tiki/kernel-ml
- OVS: openvswitch-2.6.1-4.1.git20161206.el7.x86_64
- From RDO
- tuned profile: throughput-performance
Test Overview
- Create two tunnels between the hosts: one VXLAN and one Geneve.
- With Geneve, add 1 TLV field to match the amount of additional metadata sent across the tunnel with OVN.
- Use pbench-uperf to run tests
- Traffic
- TCP
- UDP (with different packet sizes, 64 and 1024 byte)
- Multiple concurrent streams (8 and 64)
- All tests are run 3 times. Results must be within 5% stddev or the 3 runs will be discarded and will run again. This ensures reasonably consistent and reliable results.
Summary of Results
TCP Throughput
- We reach line rate with both VXLAN and Geneve. Differences are observed in CPU consumption where we see Geneve consistently using less CPU.
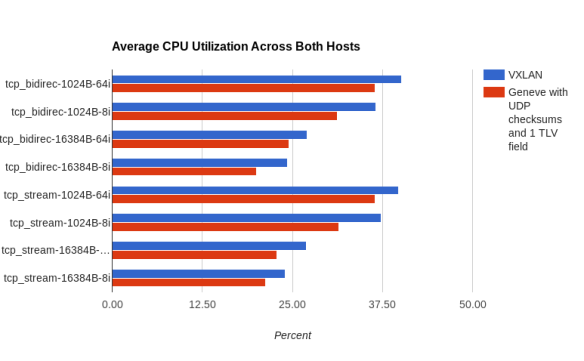
| Average CPU Utilization Across Both Hosts | |||
| Scenario | VXLAN – Average CPU Utilization (Percent) | Geneve w/ UDP checksums and 1 TLV Field – Average CPU Utilization (Percent) | Average CPU Utilization Increase (Percent) |
| tcp_bidirec-1024B-64i | 40.17 | 36.45 | -3.72 |
| tcp_bidirec-1024B-8i | 36.62 | 31.26 | -5.35 |
| tcp_bidirec-16384B-64i | 27.02 | 24.52 | -2.50 |
| tcp_bidirec-16384B-8i | 24.34 | 20.06 | -4.28 |
| tcp_stream-1024B-64i | 39.75 | 36.53 | -3.22 |
| tcp_stream-1024B-8i | 37.36 | 31.50 | -5.87 |
| tcp_stream-16384B-64i | 26.92 | 22.83 | -4.09 |
| tcp_stream-16384B-8i | 24.01 | 21.32 | -2.69 |
| Average CPU Utilization Increase (Percent) Across All Scenarios | -3.96 | ||
TCP and UDP Request/Response Rate (RR)
- We see higher CPU usage in these scenarios with Geneve, but an even higher relative amount of requests per second processed, leading us to conclude that Geneve is performing better overall in this case, as well.
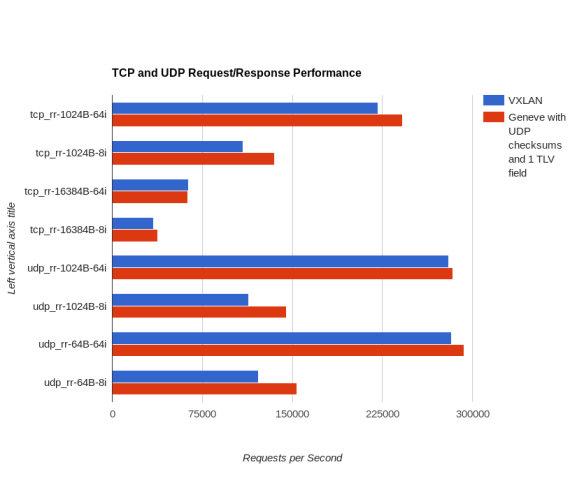
| Request / Response Performance | |||
| Scenario | VXLAN – Requests per Second | Geneve w/ UDP checksums and 1 TLV Field – Requests Per Second | Percent Increase with Geneve |
| tcp_rr-1024B-64i | 221400 | 241900 | 9.26% |
| tcp_rr-1024B-8i | 109000 | 135000 | 23.85% |
| tcp_rr-16384B-64i | 63400 | 63060 | -0.54% |
| tcp_rr-16384B-8i | 34330 | 37950 | 10.54% |
| udp_rr-1024B-64i | 280300 | 283600 | 1.18% |
| udp_rr-1024B-8i | 113600 | 145200 | 27.82% |
| udp_rr-64B-64i | 282300 | 293100 | 3.83% |
| udp_rr-64B-8i | 121600 | 154000 | 26.64% |
| Average Percentage Increase with Geneve | 12.82% | ||
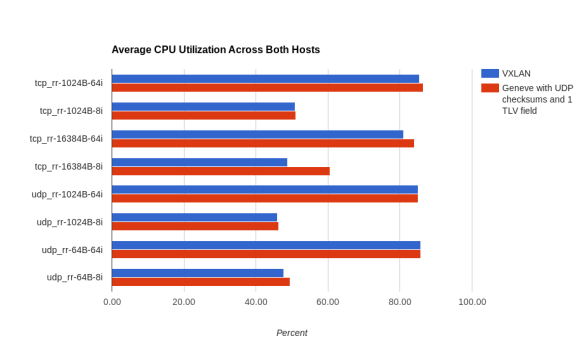
| Average CPU Utilization Across Both Hosts | |||
| Scenario | VXLAN Average CPU Utilization (Percent) | Geneve w/ UDP checksums Average CPU Utilization (Percent) | Average CPU Utilization Increase (Percent) |
| tcp_rr-1024B-64i | 85.39 | 86.49 | 1.11 |
| tcp_rr-1024B-8i | 50.94 | 51.06 | 0.13 |
| tcp_rr-16384B-64i | 81.02 | 84.04 | 3.02 |
| tcp_rr-16384B-8i | 48.84 | 60.58 | 11.74 |
| udp_rr-1024B-64i | 85.10 | 85.05 | -0.05 |
| udp_rr-1024B-8i | 45.95 | 46.38 | 0.43 |
| udp_rr-64B-64i | 85.65 | 85.71 | 0.06 |
| udp_rr-64B-8i | 47.66 | 49.43 | 1.77 |
| Average CPU Utilization Increase (Percent) Across All Scenarios | 2.28 | ||
Conclusion
Using optimizations available in newer versions of the Linux kernel, we are seeing better performance with Geneve than VXLAN, despite this hardware having some VXLAN specific offload capabilities.
Based on these results, I feel that OVN’s reliance on Geneve as its standard tunneling protocol is acceptable. It provides additional capabilities while maintaining good performance, even on hardware that has VXLAN specific RSS support.
Adding general VXLAN support to OVN would not be trivial and would introduce a significant ongoing maintenance burden. Testing done so far does not justify that cost.

Good article Russell, few comments:
1. RSS as a feature is not related to tunnels or not, its just a way of the NIC to split traffic given a hash function to few NIC queues.
Some NIC’s as you mentioned are able to look and perform RSS on the inner header of
a tunneled packet
2. in VXLAN the UDP src port is suppose to be a function of the inner 5-tuple of the packet, this was done in order to allow it to hash better for exactly such cases as you describe even without performing RSS on the inner headers.
(Nothing similar in Geneve?)
3. I believe MLX5 is going to have support for Geneve in the near future, Intel RRC already has support for it and VXLAN offload.
1) Yes, I mean RSS with the ability to distribute packets based on the inner header
2) That’s true for Linux, at least. It’s the same for Geneve. This isn’t used for receive queue distribution by default though because it breaks when there is IP fragmentation. In that case, you don’t always have the inner headers to hash on.
3) Great, thanks!
Russell, thanks for the report and analysis! I have some questions:
1) What’s the MTU configured in these tests for VM and physical interface? Is it jumbo frame (e.g. 9000) or 1500? Just to understand if high cost of TCP segmentation/reassembling are involved in this test.
2) Do you have the result of throughput for a single TCP stream (send/recv between a single pair of VMs)?
3) For tx-udp_tnl-segmentation, I wonder how could it be common for VXLAN and GENEVE, since the NIC has to decap the VXLAN or GENEVE header and then do the segmentation/reassembling. Since GENEVE has variant length header it should be much harder to support than VXLAN. So I am a little confused here, and also surprised at the result that GENEVE is even better than VXLAN. If the answer to question 1) is 9000 then this may be explained 🙂
1) 1500
2) I don’t, sorry.
3) I don’t think the NIC actually knows the details of VXLAN or Geneve. My understanding is that it’s given a template set of headers and an offset for filling in the rest of the packet with TCP segments.
Not all the protocol details, but at least the UDP port number and the offset are protocol dependent. For my understanding the offset may be difficult for Geneve since the NIC has to parse the header (Opt Len field) to know the offset. Checking kernel v4.11.3 code, mellanox drivers (e.g. [1]) enables NETIF_F_GSO_UDP_TUNNEL for VXLAN only, which suggests no Geneve support for segmentation offloading.
[1] http://elixir.free-electrons.com/linux/latest/source/drivers/net/ethernet/mellanox/mlx4/en_netdev.c#L2587
Not sure if multi-stream test covered any subtle details, but I used to compare STT (with TSO/LRO) and VXLAN (without offloading) years ago with single stream test. It achieved 9.4 Gbps out of 10G with STT but below 4 Gbps with VXLAN. I haven’t tested offloading of VXLAN, but I believed the power of TCP segmentation offloading, and assumed same power for VXLAN/Geneve offloading. It is strange that the offloading didn’t matter here.
It could be that improved availability of more generic offloads is helping too – GSO_PARTIAL in particular, as referred to here: https://netdevconf.org/1.2/session.html?alexander-duyck
Pingback: OVN – Geneve vs VXLAN, Does it Matter? – GREENSTACK
vxlan offload then lacks the feature of notifying the kernel it performed udp checksum verification on the outer packet? (I’m missing the reason why vxlan offload consumes more CPU)
UDP checksums are not typically used with VXLAN. The RFC is vague about this. It says “UDP Checksum: It SHOULD be transmitted as zero.” It goes on to say that the checksum may optionally be included. In practice, I’ve read that there are hardware implementations of VXLAN that expect the UDP checksum to be zero. It could be enabled, but there would be compatibility concerns for some environments, at least.
I’m also not sure if the optimization discussed for Geneve is available for VXLAN. Presumably it could be added if it’s not already there.
Good article.
One question I have always had about OVN and the decision to embrace Geneve vs VXLAN is: what about interoperability with other hypervisors? How can one interconnect with VMs or Containers running on something like vSphere? I must admit my knowledge may be a bit stale, but would Geneve as only option in OVN preclude the ability to have an overlay span across heterogeneous hypervisors if such hypervisors don’t all support OVN/Geneve?
OVN with Geneve works across KVM, Xen, and Hyper-V today. The Cloudbase team has demoed a mixed KVM and Hyper-V environment running with OVN.
If some other type of hypervisor can’t run OVN natively, we can do VXLAN based L2 gateways to bridge to whatever is managing that networking if needed.
Some of the NICs can support packet aggregation on receive, e.g. mlx4_en, it can reassembe vxlan packets which packet_len is MTU(1500) to 64K, that reduces the number of times into linux kernel, so a single stream can reach line rate. do we need a special hardware to do this for geneve? or other solution?
Pingback: Technology Short Take #84 – KAYENRE Technology
Pingback: NSX-T enablement – Elastic Sky
Pingback: Why GENEVE in NSX-T.. – Kurukshetra of Software Defined Networking